Are you really data driven? Here’s what I’ve learnt about making decisions using quantitative data.
A Typical Test versus Control Experiment
Let’s get on a page about what we’re discussing. Most web companies run test versus control experiments, or A/B tests. The idea is simple:
- Divide the customers into populations
- Show one population the control (default, “A”) experience
- Show one or more populations the test (new, altered, “B”) experience
- Collect data from each population
- Compute metrics from the data
- Understand the relative results between the test and the control
- Make decisions: either keep the control, or replace it with a new, better experience from a positive test

Explaining how to really know your customer with data at the 2012 eBay Data Conference
It’s critical in Step 5 to compute confidence intervals, that is, statistical measures that tell you the probability that the phenomena you’re seeing is real. For example, using a one-sided t-test, you might learn that there’s a 90% probability that the test experience is better than the control.
Let’s suppose you’ve reorganized the layout of your site, and what you’ve learnt is that customers abandon the pages much less. Through your test, you’re 90% confident that a new experience you’ve tested is better than the default, control experience. On that basis, you might want to launch the new, test experience — but I’d caution you to learn more before you make a decision.
Where does the behavior come from?
I recommend you always dig deep into your data. Learn as much as you can before you decide. I like to see data “cut” (broken into sub populations) by:
- Device (Mobile vs. tablet vs. desktop. Break it down by brand, make, and model [for example, Apple iPad HD])
- Operating system (Linux vs. Mac OS X vs. Windows, break it out by versions)
- Browser (Chrome vs. IE vs. Firefox vs. Safari, break it out by version)
- Channel (Visits from within your site vs. visits from Google search vs. Visits from paid advertising)
When you do this, and add in your confidence intervals, you will almost always learn something. Is the new experience working as expected on the dreaded IE6 and IE7? Any issues on a mobile device? Does it work better when customers are navigating within your site versus landing in the middle of it from a Google search?
Ask yourself: what can I improve before I make a decision? And always ask: knowing this detail, am I still comfortable with my decision? Be very careful about launching new experiences that help most of the population, and hurt some of it — ask whether you can live with the worst case experience.
When you do these cuts, make sure the data makes sense. I’ve learnt over the years that when you see something that you don’t expect, it’s almost always a bug, or an error in the data. Never explain away surprises with complex theories — something is probably broken.
Who or what is affected by the change?
You can think of the previous section as suggesting you cut the data funnel — where the behaviors come from. You should also cut the data by who or what it affects on your site:
- Which customers are affected? (Old versus new, first time visitors versus returning, regular versus occasional, international versus domestic, near versus far, and so on)
- What categories are affected? (Fashion versus electronics, browse versus buy, and so on)
- Which queries are affected? (A search-centric view. Long versus short queries, English versus non-English, Navigational versus Informational, and so on)
- Which sessions are affected? (Long research sessions versus short purchase sessions, multi-query sessions versus single-query sessions, multi-click sessions versus single-click sessions, and so on)
- Which pages are affected?
All the same caveats and suggestions from the previous section apply here.
I also love to compute many different metrics. While you’ll often have a “north star” metric that you’re trying to move — whether it’s relevance of the experience, abandonment of your site, or the dollar value of goods sold — it’s great to have supporting data to inform your decision. When you compute more metrics, you almost always will see contradiction that makes your decisions harder: but it’s always better to know more than to have your head in the sand. It takes smart, sensible debate to make most launch decisions.
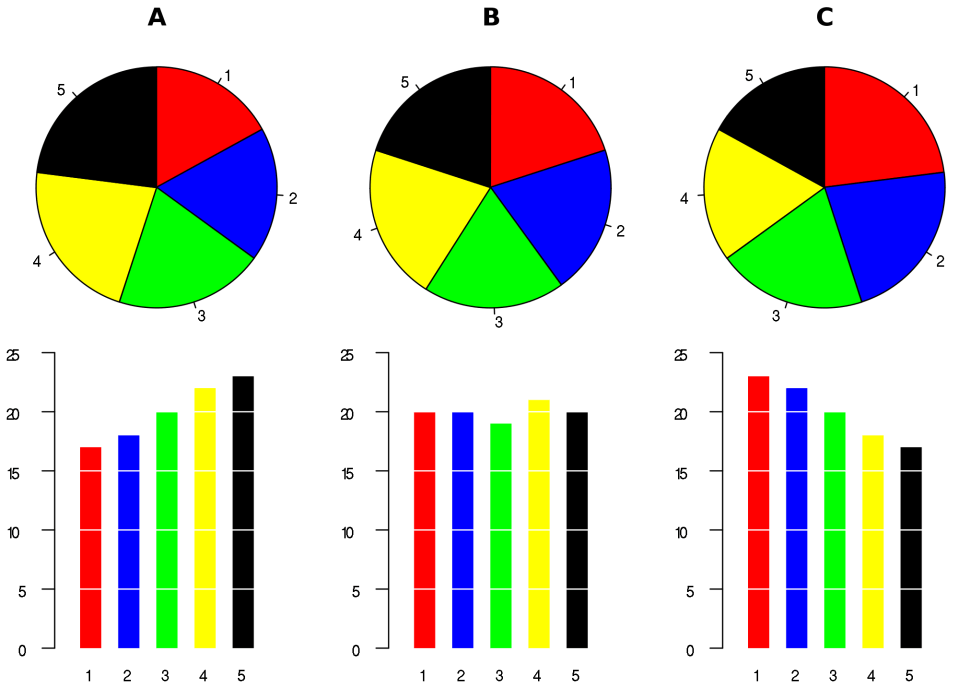
The mean average hides the truth
Here’s an over-simplified example. Suppose six customers rate your site on a scale of 1 (horrible) to 10 (amazing). In the control, they rate you as 4, 5, and 6. In the test, they rate you as 1, 4, and 10. The control and test have a mean average rating of 5. (Ignore the statistical significance for the simple example.)
On this basis, you might abandon the work on the new experience — it’s no better than the control. But if you dig in the data, you’d see that some customers love the new experience, and some hate it. Imagine if you can fix whatever is causing customers to hate it — if you could get that 1 to be a 5, you’d see a mean average of over 6 for the test. The fastest way to move a mean is to fix the outliers: focusing on what’s broken.
I don’t like mean averages because they hide the interesting nuggets. I like to see 90th and 95th percentiles — show me the performance of the best and worst 10% or 5% of customer experiences respectively. In our simple example, I’d love to know that the worst customer experience was 1 in the test and 4 in the control, and the best experience was 10 and 6. Knowing this, I’m, excited about the potential of the test, but worried that something is very wrong about it for some customers. That guides me where to put my energy.
Don’t be myopic
It’s common to measure your feature in the product, and ignore the ecosystem. For example, you might be working on an improvement on some part of a page — imagine that you’re working on Facebook’s news feed. You’ve figured out an improvement, run the test, seen much better customer engagement, and you’re excited to launch.
But did you worry about what you’ve done to the sponsored links on the right side of the page? Did you hurt the performance of another part of the product owned by another team? It’s common for features to hurt performance of others, and often cause the overall result to be neutral. This happens between features on one page, and between pages. Make sure you always measure overall page and site performance too.
Tests don’t tell you everything
Tests don’t tell you what you don’t measure. Measure as much as you can.
Even if you do measure as much as you can, there’ll be much happening outside your test that’s important. For example, if you run a test for a week, you don’t learn anything about the long term effects on customer retention. You don’t know anything about how customers will adapt to using the feature. You won’t know whether the effects are seasonal, or what might happen if some of your assumptions change — for example, what if another team changes something else on the page or site in the future?
This can be ok. Just realize the limitations, and be aware that retesting in the future might be a smart choice.
Quantitative testing also won’t tell you anything qualitative about what you’re working on. That’s a whole another theme of testing — and one I do plan to come back to talk about in the future.
Afterword
Around 1,000 people attended the employee-only eBay Data Conference recently. I had the opportunity to speak to them through my opening keynote address, and this post is based on that presentation. Thanks to Bob Page for inviting me.